
When you program simple microcontrollers as if they were fancy computers, which can do crazy computational stuff like multiplication, you are in for some surprises. Here’s one of those surprises, plus a solution.

Once upon a time I designed a round PCB with twelve LEDs on it, controlled using the Charlieplexing method by a PIC16 microcontroller. With charlieplexing – unless you’re really l33t – only one LED can be lit at any given moment. Therefore, to prevent flicker, each LED has to be “refreshed”, say, fifty times a second. I also wanted to have sixteen levels of perceived brightness, so all in all, the code had to perform 12x50x16 individual LED updates per second. For an MCU that does millions of operations per second, that shouldn’t be too difficult: plenty of processing time left for fun stuff, like rotating the lights around the PCB.
With the hardware ready, I turned to the MPLAB X IDE and wrote a little C program to control the light show. Very clear code, if I may say so myself, with a neat array of twelve structs containing all the information needed to handle each LED. The code worked… but it was unexpectedly sluggish. Of course, there can be a hundred reasons for a sluggish code, but all clues led to what struck me, initially, as a strange conclusion: The mundane fetching of bytes from the LED data array was taking way too long. I opened up the Assembly listing and this is what I found:
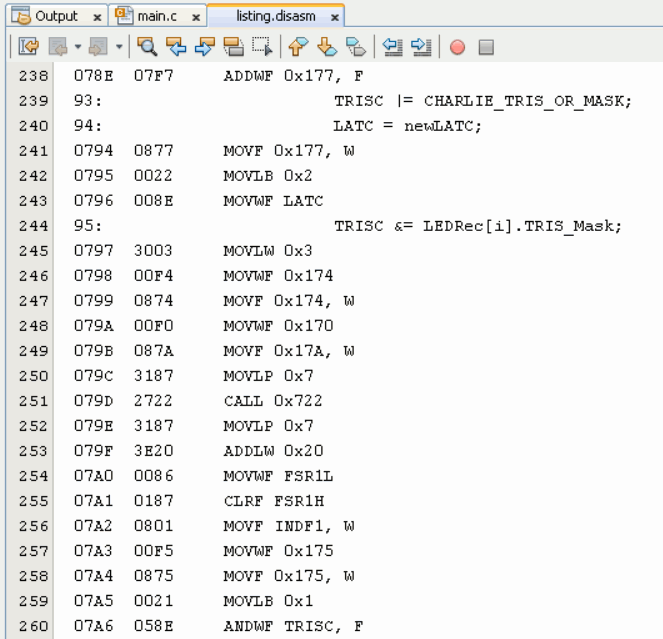
The line beginning with “95:” is from my source C code, and the Assembly beneath is what the compiler made of it. It’s not just lots of commands – there’s even a CALL in there, that sends us to a subroutine with additional commands. What does it all do, you ask? Multiplying two numbers. That’s it.
You see, I should have remembered that simple MCUs, like the PIC16 family, or even the Maker’s Favorite ATtiny85, are so simple that their hardware can’t even multiply integers. It has to be done in software (basically, bit-shifting and adding repeatedly, while keeping an eye on the integer type). That takes a lot of clock cycles.
Now, you may have noticed that there’s no explicit multiplication in that line of code. But it is there, implicitly: the code accesses the struct at index i. the size of each struct in that array is larger than one byte – let’s call that size n, so to figure out the exact address in memory of that particular struct, the code has to know how much is i times n. The XC8 compiler, even in its free version, attempts to optimize such calculations in various ways, but it’s not always possible, or enough. We are left with what could easily be dozens of extra operations for each such access.
If we need the data fast and can’t afford the delay, the obvious solution would be to ditch the struct altogether. If it contains variables X, Y and Z, then we’ll create instead three separate arrays, called X, Y and Z respectively, and take our data from them. Even if the data types in these arrays are two or four bytes in size, the calculation is still much easier and, therefore, faster. The flip side, of course, is that our source code becomes messier, and harder to follow and maintain.
An even better solution would be to keep the original struct array, but add a separate array of pointers-to-struct, and assign the appropriate values to them during the program startup. All access to the data will be done through these pointers. Fetching a pointer from this array by its index is fast, and then we have immediate access to the relevant data!
Here are some actual, real-life numbers to demonstrate the effect of such changes. With the specific MCU and clock speed I used, fetching a single byte from an array of structs, the “usual” way, took 360μs. Fetching the same data using the pointer array took only 40μs. For as 32-bit variable, the respective numbers were 370μs vs. 70μs. This is not a difference to be trifled with.
Here’s a generic little C program, that initializes and uses a an array of pointers pointing to an array of structs. You can also copy it here.

Finally, since there ain’t no such thing as a free lunch, here are a couple of little gotchas for this technique. The pointer array itself uses up memory space, and if there are lots of structs to point to (in FLASH, for example) then the pointers may take too much of what little SRAM we have. Also, initializing the pointers the easy way (e.g. “pMyStruct[n] = &myStruct[n]” in the code above) will require sofware-based multiplication, so the compiled code will be bigger, and the power-up or restart times will be longer too. This may or may not be important, depending on the application.
One last thing: you might ask – why not declare only the pointer array, and then malloc() memory for each pointer? It can be done of course, but dynamic memory allocation isn’t too graceful on such simple MCUs, and if you need to initialize the data to known values, the initialization code might turn ugly too.
That’s it for now – happy coding!
Why not pad the original struct to make **n** a power of two?
Sorry for the late reply, I didn’t get a notification about this comment… anyway, with these microcontrollers having typically 1KB of RAM or less, any kind of padding is problematic. But if the specific application allows it, yes. that could work too.