
כשהדרישות מהמערכת דוחקות אותנו ממש לפינה, אפשר לפעמים לסחוט עוד כמה מחזורי שעון אפילו מדבר בסיסי כמו פקודת switch בשפת C. ולפעמים אי אפשר. בואו נצלול לעומק שני קומפיילרים כדי לגלות אם, מתי ואיך אופטימיזציה קיצונית שכזו יכולה לעבוד.
לפני זמן-מה, בעודי יושב ומחכה לילדים שייצאו מהחוג, העברתי את הזמן בשיחה עם אחד הממתינים האחרים על ענייני דיומא: המידע החדש על הפצצת הכור הגרעיני בסוריה, פרטים אדמיניסטרטיביים על החוג, וכמובן, אופטימיזציה של קוד. האיש, שהוא לגמרי במקרה מתכנת רציני מאוד בחברת ענק, הזכיר בין השאר משהו שלא חשבתי עליו עד אז, ושיכול להיות מעשי גם בתכנות של מיקרו-בקרים 8-ביט צנועים: מה קורה כשאנחנו בודקים ערך של משתנה באמצעות מבנה switch/case.
למי שצריך תזכורת: נניח שיש לנו משתנה בשם x שמכיל תו אחד בלבד, והתוכנה שלנו צריכה באיזשהו שלב לבצע פעולות שונות בהתאם לערך שנמצא ב-x. אם מדובר על ערך אחד, שניים או אפילו שלושה, אפשר לכתוב את הקוד הזה כשרשרת של תנאי if/else:
if (x == 14) {
// some code...
} else if (x == 51) {
// Some other code...
} else if (x == 222) {
// some different code...
}
// ...and so on.אבל מספר גדול יותר של ערכים אפשריים הופך קוד שמבוסס על if/else לבלתי קריא, מוּעד לבאגים וקשה מאוד לשינוי. במקומו, אנחנו יכולים לכתוב משהו כזה:
switch (x) {
case 14 : // Some code...
break;
case 51 : // Some other code...
break;
case 222: // Some different code...
// ...and so on.
}הרבה יותר קריא, בהחלט. אבל איך הקומפיילר יכול לממש אותו? ובכן, הפתרון הקל ביותר הוא פשוט לתרגם את המבנה הזה לשרשרת מקבילה של if/else, ולממש אותה כסדרה של השוואות וקפיצות בשפת המכונה. למעשה, סביר להניח שזה מה שמתבצע בפועל – אלא אם הנסיבות מאפשרות אופטימיזציה אוטומטית ניכרת, לדוגמה אם הערכים הנבדקים הם עוקבים (כגון "A", "B", "C").
נניח שהקומפיילר הפך את ה-switch ישירות לשרשרת if/else. המשמעות היא שאם הערך של x הוא, במקרה, הראשון בשרשרת, הוא יאותר מייד. לעומת זאת, אם הערך הוא במקרה דווקא האחרון בשרשרת, המעבד יצטרך לבדוק את כל האפשרויות אחת-אחת עד שיגיע אליו. בהנחה שיש N ערכים אפשריים ל-x ושלכל ערך יש סיכוי שווה להופיע כשהבדיקה מתחילה, אז בממוצע נצטרך (N-1)/2 בדיקות בכל פעם (הערך האחרון אינו מחייב בדיקה – אם עברנו את כל שרשרת הבדיקות ולא מצאנו את הערכים שבהן, הערך האחרון שנשאר חייב להיות הנכון). אבל מה קורה אם לערכים מסוימים יש סיכוי גדול הרבה יותר להופיע מאשר לאחרים? במצב כזה, סידור נכון של הערכים ב-switch, בסדר יורד של שכיחוּת הופעתם, יכול לכאורה לחסוך המון בדיקות ומחזורי שעון. למעשה, בתנאים מסוימים הוא יכול לשפר את ביצועי המערכת כולה ואף למנוע צווארי בקבוק.
עד כאן זהו רעיון תיאורטי, וחשוב לזכור שקומפיילרים מודרניים הם חכמים מאוד ויכולים להכניס הרבה שינויים ושיפורים לא צפויים. מי שרוצה מוזמן לבדוק אם הרעיון התיאורטי נכון "בשטח" באמצעות מדידת זמנים במחשב, על ארדואינו וכדומה. אני בחרתי להיכנס לעומק ולבחון את פלט הקומפיילר XC8, שמיועד למיקרו-בקרים 8-ביט ממשפחת PIC. הגרסה שאיתה עבדתי כאן היא 1.45, וזו המהדורה החינמית שלא עושה הרבה אופטימיזציות (ויש הטוענים שאף מכניסה עיכובים לקוד). הנה הקטע הרלוונטי בתוכנה שלי:
switch (x[j]) {
case 'A' : ++n[0];
break;
case 'B' : ++n[1];
break;
case 'C' : ++n[2];
break;
}את ה-break האחרון, שאינו חיוני, הוספתי למען האחידות. הנה פלט האסמבלי שהקומפיילר הפיק עבור בדיקות הערכים של הקטע הזה:
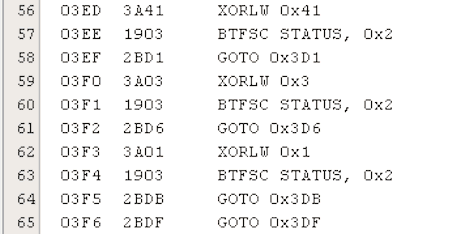
זה כבר מצריך כמה הסברים. בשורה 56 (המספור הוא בטור הכי שמאלי), הפקודה מבצעת פעולת XOR של הרגיסטר W עם הערך 0x41. כידוע, 0x41 בייצוג עשרוני הוא 65, וזה קוד ה-ASCII של התו "A" – כמו ב-case הראשון שלנו. הפקודה הבאה, BTFSC, היא תנאי שבודק מה הערך של ביט מסוים ברגיסטר מסוים – במקרה זה ביט 2 ברגיסטר STATUS. עיון ב-Datasheet מגלה שהביט הזה אומר לנו אם התוצאה של הפעולה החשבונית/לוגית האחרונה היא 0. אם התנאי מתקיים – במילים אחרות, אם פעולת ה-XOR בין W לבין 0x41 הניבה 0, מה שאומר שהערך שהיה ב-W בהתחלה היה גם כן 0x41 – אז הפקודה BTFSC תעביר את השרביט לפקודה שאחריה, בשורה 58. לעומת זאת, אם התנאי לא מתקיים, הפקודה הבאה שתתבצע היא השנייה בתור – זו שבשורה 59.
עד כאן יש? יש. עכשיו, שורה 58 שולחת אותנו לפקודות שלא מופיעות בתמונה, ושמתאימות למקרה הראשון ("מצאנו את הערך A"), ואילו שורה 59 ממשיכה בבדיקות. היא עושה XOR של W עם הערך 3, ושוב יש לנו BTFSC שבודק אם יצא 0 ומפנה הלאה למקום המתאים. אבל מה פתאום XOR עם 3? מאיפה הגיע ה-3 לכאן, אם אנחנו מחפשים בכלל את "B" שערכו 66? ובכן, הפקודה XORLW משנה את הערך של W, וקודם הרי עשינו לו XOR עם "A", אז אם הוא היה בהתחלה "B" אנחנו צריכים לחפש עכשיו ערך חדש – את התוצאה של XOR בין "A" ל-B". ניחשתם כבר? יפה מאוד, זה 3.
אחרי זה יש לנו שוב את אותו התהליך עבור "C", וגמרנו את הקטע הזה. למה כל ההתעסקות עם XOR? בהתחשב בכך שה-PIC בו השתמשתי מכיר רק 35 פקודות אסמבלי שונות, סביר להניח שאין יותר מדי גמישות והקומפיילר פשוט חייב להסתדר עם מה שיש. הוא הפך את קוד ה-C שלי לאסמבלי בצורה מעניינת ולא לגמרי טריוויאלית, אבל – וזה החלק החשוב – נראה שהוא שמר על הסדר המקורי של בדיקות הערכים.
וכעת לשאלת מיליון מחזורי השעון: מה יקרה אם אהפוך את סדר הערכים ב-switch המקורי? לא אשאיר אתכם במתח, הנה התשובה:
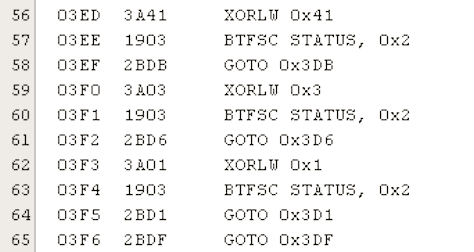
לא, לא שמתי כאן בטעות את אותה התמונה. שימו לב לכתובות שפקודות ה-GOTO מובילות אליהן לעומת התמונה הקודמת. הכתובות השתנו כיוון שהקומפיילר מיקם את קטעי הקוד הרלוונטיים לכל אופציה לפי סדר הופעתם ב-switch… אבל לעזאזל, את הערכים עצמם הוא מיין מראש לצורך סדר הבדיקות! זאת אומרת, האופטימיזציה התיאורטית היפה לא תעבוד עם הקומפיילר הספציפי הזה, כי הוא מתחכם וממיין את הערכים לפי ההיגיון שלו ולא שלנו. וידאתי את זה גם עם ערכים לא עוקבים.
אוקיי, ומה יקרה במיקרו-בקרים 8-ביט ממשפחת AVR, למשל ATtiny85 האהוב? כתבתי קוד C מקביל ב-Atmel Studio, עם הערכים ב-switch לפי סדר ה-ABC. הקוד שהופק הרבה יותר מורכב ומפותל. הנה חלק ממנו, וסימנתי בחץ את ההשוואה הראשונה מתוך השלוש:
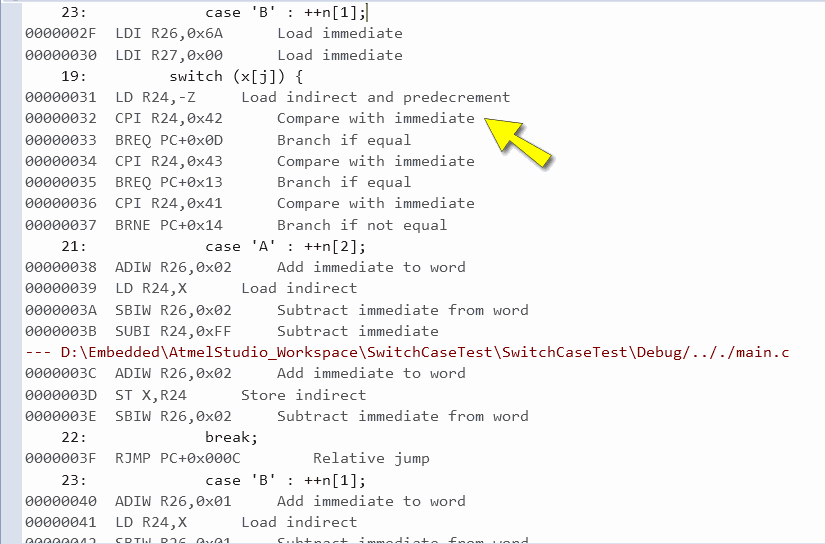
גם בלי להבין מה בדיוק קורה פה (למה לכל הרוחות הקוד לאופציה "B" מפוצל לשני חלקים?) קל לראות שסדר הבדיקות השתנה: הערך הראשון שנבדק הוא "B", אחריו "C" ורק בסוף "A". למה? לאלוהי gcc פתרונים, אבל המסקנה ברורה: גם כאן אי אפשר לבצע אופטימיזציה על ידי שינוי סדר הבדיקה ב-switch, כי הקומפיילר שם עליו פס.
זה לא אומר שהכול אבוד, אבל זה כן אומר שעם השטיקים של הקומפיילרים המודרניים, אסור להניח שקוד ה-C שלנו יתורגם ויבוצע בדיוק כמו שאנחנו מדמיינים. אופטימיזציה של סדר בדיקות כשהתפלגות הערכים אינה אחידה היא דבר שיכול לעבוד, אך רק בתנאי שאנחנו יודעים בדיוק מה אנחנו עושים – ומה הכלים שבהם אנחנו משתמשים עושים. המתכנת שאיתו דיברתי, לדוגמה, שינה בזמנו את הקוד של הקומפיילר עצמו כדי שיממש את switch בצורה היעילה ביותר ליישום שלו!