
לראשונה בסדרת הפוסטים הזו, אנחנו משתמשים במודול חומרה שאין לו מקבילה במיקרו-בקרים ה"קלאסיים" של ארדואינו: מודול הגישה הישירה לזיכרון (DMA). לצורך ההדגמה, נבצע בעזרתו משימה נפוצה ושימושית – שידור מחרוזת תווים דרך מודול ה-UART.
לפני שנתחיל, עדכון (תרתי משמע): סביבת הפיתוח הרשמית MounRiver Studio, שבה אני משתמש לעבודה עם מיקרו-בקרי CH32V00x, התקדמה לגרסה 2, ואם אתם עדיין משתמשים בגרסה קודמת, לא תקבלו שום הודעה על כך – צריך להוריד לבד את קובץ ההתקנה מהאתר. ההבדל בין הגרסאות משמעותי, ולדעתי הממשק בגרסה החדשה הרבה יותר נקי ונעים.
מה זה DMA
חלק גדול מאוד מהעבודה של כל ליבת מחשב (או מיקרו-בקר) קשור לא לעיבוד וחישובים, אלא דווקא להזזה פשוטה של נתונים גולמיים אל זיכרון ה-RAM (או SRAM) וממנו . כדי לא לבזבז יותר מדי זמן על ההזזה הזאת המציאו מעקף שנקרא Direct Memory Access, בראשי תיבות DMA. זהו מודול חומרה שבעצם מעתיק נתונים בצורה סדרתית בין הזיכרון לבין מודולים אחרים, או אפילו בין שני מקומות שונים בזיכרון, בלי שנצטרך לכתוב בעצמנו לולאות ופקודות קריאה וכתיבה ישירות. זה לא רק חוסך שורות קוד, אלא גם מאפשר מעין עבודה במקביל – הקוד יכול להמשיך לרוץ בזמן שההעתקה מתבצעת. אבל שימו לב שמימושי DMA מסוימים, בעיקר במיקרו-בקרים, עשויים לעבור בכל זאת דרך ה-CPU, או לפחות דרך אותו Bus שמשמש את ה-CPU לגישה לזיכרון, ולכן הם כן מאטים קצת את הקוד ה"רגיל".
בהרבה מיקרו-בקרים 8-ביט, כולל משפחות ATmega ו-ATtiny המוכרות, ויתרו לגמרי על DMA. לעומת זאת, בשבבים חזקים/מתקדמים יותר, ה-DMA הוא מודול סטנדרטי לגמרי, וכך גם במשפחת CH32V00x.
עקרונות הפעולה של DMA
בגדול, הפעלת ה-DMA אמורה להיות פשוטה, מעין "שגר ושכח": מגדירים למודול כתובת מקור וכתובת יעד, אומרים לו כמה בייטים להעתיק מפה לשם, ונותנים פקודה להתחיל. אך כמובן שבמציאות זה יותר מורכב. למשל, אם מעתיקים נתונים בין שני מיקומים באותו זיכרון SRAM, הגיוני שה-DMA יעבוד במהירות מקסימלית – אבל אם מעתיקים מה-SRAM אל ה-UART כדי לשדר את הבייטים החוצה, צריך להתחשב בקצב השידור של ה-UART עצמו, שכמובן מהווה מגבלה משמעותית מאוד. לכן, סביב ה"ליבה" של העתקת בייטים יש עוד כל מיני הגדרות, סיגנלים ופרמטרים שצריך להכיר.
הגדרות DMA כלליות ב-CH32V003
נתחיל בהגדרות שמשותפות, פחות או יותר, לכל פעולות ה-DMA. לשבב שלנו יש מודול DMA יחיד, שנקרא DMA1, ויש לו שבעה ערוצים (Channels). כל ערוץ יכול לפעול באופן עצמאי, אבל כיוון שכולם שייכים לאותו מודול, אם שניים או יותר פועלים "בו-זמנית", הם יוצרים תור פנימי שיש לו (איך לא) השפעות על המהירות. בנוסף, כל ערוץ יכול להתחבר רק למודולים פריפריאליים מסוימים, לפי הטבלה הבאה:
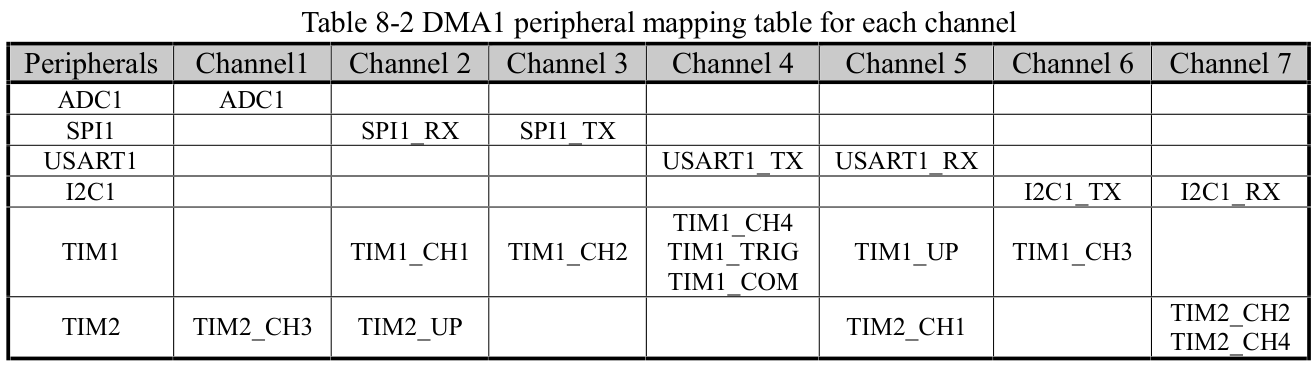
מהטבלה אנו למדים שרק ערוץ 4 יכול לגשת ל-TX של ה-UART, אז נזכור שזה הערוץ שמעניין אותנו.
כמו כל מודול פריפריאלי, גם את DMA1 חייבים לחבר לשעון המערכת לפני שעושים איתו משהו. החיבור נעשה באמצעות כתיבת "1" לביט DMA1EN (ביט מס' 0) ברגיסטר RCC->AHBPCENR. בקוד זה נראה ככה:
RCC->AHBPCENR |= RCC_DMA1EN; עכשיו אפשר להגדיר את הכתובות עבור הערוץ שאנחנו מפעילים. אחת נקראת PADDR (ה-P זה Peripheral, אבל לא חובה – רק אם משתמשים במודול פריפריאלי) והשנייה נקראת MADDR. בשביל הדוגמה הגדרתי בקוד שלי מחרוזת (כמערך בייטים) שנקראת msg – היא נמצאת כמובן בזיכרון וה-DMA יעתיק ממנה:
uint8_t msg[14] = "Hello DMA :)\n";והיעד הוא הרגיסטר USART1->DATAR, שאליו כזכור כותבים בייטים כדי לשלוח אותם דרך UART. אז נקצה את שתי הכתובות הרלוונטיות האלה לערוץ 4:
DMA1_Channel4->PADDR = (uint32_t) &(USART1->DATAR);
DMA1_Channel4->MADDR = (uint32_t) msg;וגם נגיד לערוץ כמה בייטים להעביר, באמצעות הרגיסטר CNTR. המונה הזה, אגב, יורד מהערך שנותנים לו עד לאפס, ולכן צריך לתת לו ערך כל פעם מחדש, לפני כל העברה:
DMA1_Channel4->CNTR = 13;כתובת המקור בזיכרון אמורה להשתנות (כדי לעבור על המחרוזת מתחילתה ועד סופה), אבל הכתובת של היעד חייבת להישאר אותו הדבר לאורך כל הפעולה. ברגיסטר CFGR של הערוץ יש שני ביטים, MINC ו-PINC (מס' 7 ו-6, בהתאמה), שקובעים אם הכתובות MADDR ו-PADDR יקודמו אוטומטית בזמן ההעברה או לא. במקרה שלנו נרצה שרק MADDR תקודם, אז נכתוב "1" ב-MINC. ביט חשוב נוסף באותו רגיסטר הוא DIR (ביט מס' 4), שאומר אם הנתונים יועתקו מהזיכרון (ערך "1") או אל הזיכרון ("0"). זאת אומרת, מ-MADDR ל-PADDR או להיפך. אנחנו נרצה שגם הביט הזה יהיה "1". שימו לב גם לביט MEM2MEM (מס' 14), שצריך להיות "1" אם תרצו לבצע העברה בין כתובות בזיכרון בלבד.
DMA1_Channel4->CFGR |= DMA_CFG4_MINC + DMA_CFG4_DIR;כדי להתחיל את ההעברה בפועל, נכתוב "1" לביט EN (מס' 0) באותו רגיסטר:
DMA1_Channel4->CFGR |= DMA_CFGR1_EN;ואיך נדע מתי ההעברה הסתיימה? אפשר להשתמש בפסיקה ייעודית, או פשוט לדגום את הביט TCIF4 (ביט מס' 13, ראשי תיבות של Transmission Complete Interrupt Flag לערוץ 4) ברגיסטר DMA1->INTFR עד שהוא יהיה "1". אבל, חשוב מאוד – הוא לא מתאפס מעצמו כשמתחילים העתקה, אז לא לשכוח לאפס אותו בעצמנו לפני כן, באמצעות כתיבת "1" לביט CTCIF4 המקביל, ברגיסטר DMA1->INTFCR!
// Clear "Transmission complete" flag
DMA1->INTFCR |= DMA_CTCIF4;
// To check if the transmission is complete,
// if (0 != (DMA1->INTFR & DMA_TCIF4)) ...הגדרה מצד ה-UART עבור DMA
אמרנו שרק ערוץ 4 של ה-DMA יכול לעבוד עם TX, אבל הוא יכול לעבוד גם עם טיימר TIM1. אז איך מוודאים שדווקא הסיגנלים של ה-UART (ליתר דיוק, הסיגנל שאומר "גמרתי לשלוח בייט, אפשר לתת לי עוד אחד") יעברו לערוץ הזה?
זה מתבצע מצד ה-UART, באמצעות הביט DMAT (ביט מס' 7) ברגיסטר USART1->CTRL3. ה-T בשם הבייט מתייחס ל-TX, כלומר כשהביט הזה הוא "1", הסיגנל הרלוונטי לשידור יועבר למודול ה-DMA:
USART1->CTLR3 |= USART_CTLR3_DMAT;מה עדיף?
בהנחה שהגדרנו את ה-UART עצמו כמו שצריך (פינים, קצב שידור וכדומה), קטעי הקוד למעלה הם כל מה שנדרש כדי לשדר את המחרוזת דרכו באמצעות ה-DMA. זו בעצם השיטה השלישית לשדר מחרוזת. הראשונה היא באמצעות לולאה חוסמת (blocking) או מבוססת polling בקוד הראשי, והשנייה היא באמצעות פסיקות, כפי שראינו בפוסט על ה-UART. אז מי מהן עדיפה, ומתי?
מבחינת גודל הקוד (מקומפל) ומבחינת זמן מעבד והפרעה לתהליכים אחרים, ברור שה-DMA הוא המנצח, אפילו אם הוא גוזל קצת מחזורי שעון ולא עצמאי לגמרי. כניסה ויציאה מפונקציית פסיקה הן פשוט יקרות יותר. עם זאת, ההבדל אינו עצום, וכשמדובר על UART צריך להגיע למצבים די קיצוניים כדי שנהיה באמת חייבים להשתמש ב-DMA.
מצד שני, ה-DMA מוגבל יותר מהאופציות האחרות, בכך שהוא מכריח אותנו להגדיר מראש כמה בייטים יישלחו. אם השידור דורש, מאיזו סיבה שלא תהיה, גמישות גדולה יותר, אנחנו בבעיה. גם זה מצב די נדיר, אבל הוא יכול לקרות.
לסיכום, ה-DMA נמצא שם ופשוט יחסית להפעלה, אז למה לא להשתמש בו – אבל סביר להניח שהוא יככב ביישומים שצריכים העברות מהירות יותר מאשר UART טיפוסי, כגון העברות פנימיות בזיכרון, תקשורת SPI וכדומה.
נ.ב.
א. המחרוזת בקוד הדוגמה שמורה בזיכרון ה-SRAM. במסגרת הניסויים הגדרתי אותה גם כ-const כדי שתישמר ב-FLASH (פירוט תוצאות הקומפילציה הוכיח שזה אכן קרה), וגם אז ה-DMA קרא אותה בלי בעיה. כמובן שאם ננסה לכתוב לכתובת ב-FLASH, זה לא ייגמר טוב.
ב. ביקשתי מבינה מלאכותית – הפעם Copilot – קוד ל-CH32V003 שיכול לשלוח מחרוזת דרך UART באמצעות DMA. גם הפעם, כמו בפוסט הקודם, קיבלתי תשובה שנראית יפה ומסודרת, אבל עם שמות רגיסטרים שגויים, מספר פעולות קריטיות חסרות, ועוד.
ה-DMA הוא מודול מגניב ממש שיכול לאפשר ביצועים יפים במשימות "מונוטוניות" ממעבדים יחסית חלשים. מגניב שהפעלת אותו פה בצורה פשוטה וברורה, כי יש לו נטיה להראות כמו משהו מורכב ומפחיד 🙂 לדעתי בבקרים האלה ה-DMA מככב באמת בקריאות מהירות מה-ADC, שהמעבד היה כנראה קורס תחתיהן. בפרט אפשר להגיע לפחות ב-STM32F0XXX ודומיו לקצב של כמעט 5MSPS אם מתפשרים על רזולוציה של 8 ביט ומסדרים את השעונים וההגדרות נכון (הרבה יותר מה-1MSPS שהיצרן מתחייב שיעבוד בכל מצב כמעט שהשעון בו מהיר מספיק) ואין כמעט סיכוי שהמעבד יצליח לעשות משהו מעניין עם זה כשהוא גם צריך לבזבז זמן על העתקות או פסיקות של… לקרוא עוד »
לא רק נטייה, המודול הזה באמת מורכב. יש בו אלמנטים שהתעלמתי מהם לגמרי בפוסט הזה כדי לא לסבך אותו יותר מדי (גודל יחידה להעתקה, כתובות מחזוריות, פסיקות שגיאה ועוד). אבל כמו תמיד, מרגע שתופסים את הרעיון הכללי, אפשר להתחיל בקטן ולהשתלט על הנושא בהדרגה. לגבי ADC, זה אכן משהו שקורה מהר ולכן מועמד טבעי ל-DMA, השאלה היא מה צריך לעשות עם המידע. במיקרו-בקרים מודרניים יש מודולי ADC שיודעים לחפש ערכי סף ולעשות כל מיני ממוצעים בעצמם, מה שלפעמים מייתר לגמרי את כתיבת המידע הגולמי לזיכרון – ולעומת זאת אם אתה כן צריך אותו, אז בסופו של דבר ה-DMA רק יוצר… לקרוא עוד »
גם הטיימרים לרוב מאוד מורכבים, אבל פונקציונליות פשוטה שלהם מוצגת הרבה יותר מאשר DMA לתחושתי.
ולגבי ה-adc, בלי dma לא יהיה לך זמן לשום עיבוד כלשהו של הדגימות בקצב הזה. זה נכון שרוב היישומים הפשוטים שאני חושב עליהם לא דורשים קצב דגימה גבוה מלכתחילה, אבל אם אתה צריך אז ה-dma דרוש, מה גם שפתרונות אחרים יהיו כנראה מורכבים ויקרים יותר כמעט בוודאות.
הבנתי – האמת שאף פעם לא קראתי לעומק מדריכים "מעשיים" על DMA, אז אני לא יודע אילו דוגמאות מציגים בהם בדרך כלל. ונכון, גם טיימר יכול להיות מורכב מאוד כשנכנסים לעומק הדברים 🙂